New Release

Table of Contents
Get weekly insights on modern data delivered to your inbox, straight from our hand-picked curations!



the following is a revised edition.
This piece is a community contribution from Dylan Anderson, a strategy consultant and data storyteller who excels at bridging the gap between data and business strategy. With a passion for translating complex data into actionable insights, Dylan shares his expertise on LinkedIn and his blogs, The Data Ecosystem and Medium. We’re thrilled to feature his unique insights!
We actively collaborate with data experts to bring the best resources to a 9000+ strong community of data practitioners. If you have something to say on Modern Data practices & innovations, feel free to reach out! Note: All submissions are vetted for quality & relevance. We keep it information-first and do not support any promotions, paid or otherwise!
Feature Your Ideas!
A lot of people talk about the future of data being product-focused.
This means treating data like a product—aligning it with business use cases, making it accessible, promoting usability, ensuring security, and all the other things people mention when they talk about product management.
And this focus on these qualities occurs whether you define a data product as an analytical solution (classic definition) or an accessible dataset (Data Mesh approach). Note for the purposes of this article we will be taking the classic approach, with the reasoning explained in another article.
But the problem is that data product delivery is hard. Take the recent AI boom. Every large organisation with some budget set up a team to deliver AI products, thinking they would be the next OpenAI. A year later, many of those teams disbanded (I know a few), a ton of the projects wound down, and most products didn’t demonstrate the value that was promised or expected.
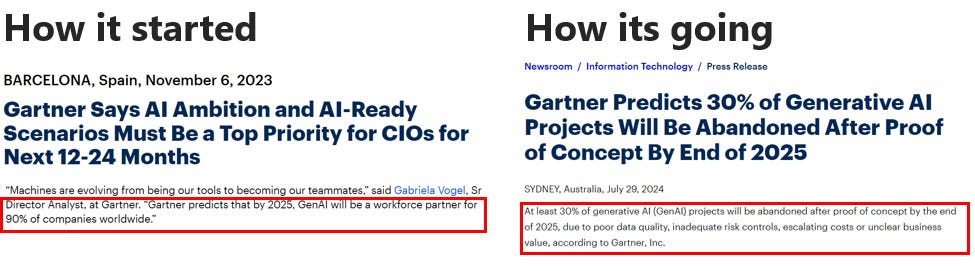
The problem isn’t constrained to AI, either. As a consultant, a good chunk of my firm’s revenue is made by building data products for clients who can’t do it themselves. This is everything from dashboards, reporting tools, machine learning algorithms, and other analytical solutions.
What is the reason for this inability to deliver internally?
Companies haven’t figured out the right delivery operating model. Their waterfall process doesn’t fit the business needs, and shouting agile over and over again without implementing it properly doesn’t work. Moreover, they lack the foundational elements required to construct data products on top.
So today, we are going to break it down and explain how to build production-ready data products with the right operating model and delivery process. Buckle up, data friends!
Before diving in, we must briefly explain what we are building.
As I’ve mentioned, data is a dynamic ecosystem in which each domain contributes to, and is influenced by, the whole. This ecosystem contains different types of participants and stakeholders, marked by complex relationships with both data and each other.
Therefore, you have to take a holistic approach that encapsulates both the data landscape and the larger business context. Consequently, in its purest sense, a data product must be a tool or solution from which end business users can draw insights and make decisions.
To explain this, I have defined the six most popular categories of data products:
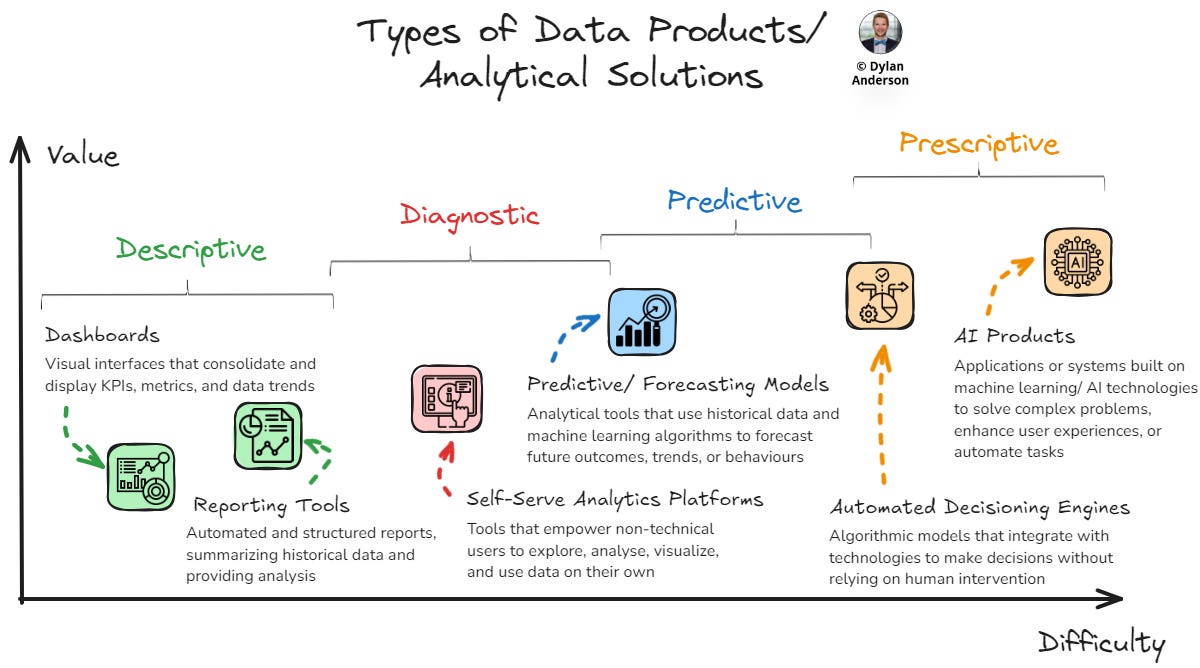
Visual interfaces that consolidate and display key performance indicators (KPIs), metrics, and data trends in real time.
Technology that generates structured reports, often summarising historical data and providing analysis based on business requirements.
Tools that empower non-technical users to explore, analyse, visualise, and use data independently.
Analytical tools that use historical data and machine learning algorithms to forecast future outcomes, trends, or behaviours.
Often leveraging predictive models, these automated algorithmic solutions integrate with technologies to make decisions without relying on human interventions.
Applications or systems built on machine learning/ artificial intelligence technologies (e.g., natural language processing, computer vision, large language models, etc.) to solve complex problems, enhance user experiences, or automate tasks. These products learn from data and adapt to new information to provide better results for the user.
Contrary to the data-as-a-product perspective, I view these solutions as the products and the data that feeds them as raw materials. These raw materials are processed and curated to enhance the value of the end products that business stakeholders use.
📝 Editor’s Note
To remove any conceptual silos (which is often hazardous given the information overwhelm of our times), we wanted to connect the dots with our former community contributions with some additional context.
A data product is different from traditional consumable data given how it’s a vertical slice of the data infrastructure, cutting across the stack, from ingestion points and infra resources to the final consumption ports. This is to induce interoperability and reusability. And as Dylan highlighted, raw data is akin to raw material for this product.
Example: A Dashboard that is a Data Product is A Dashboard coupled with
(1) Infrastructure
(2) Code that runs the dashboard
(3) Ready-for-Consumption Data +Metadata
(4) Output ports (where the said Dashboard is equal to an o/p port)
Learn more here!

Now that we have defined what data products are, we can go build them, right?
Most people would rightly say: “No, you can’t.” Unfortunately, those same people who’d do it anyway because leadership wants to “prove value” and “become data-driven.”
So, instead of jumping straight to developing data products, teams need to ensure the foundations are in place to build in a scalable and impactful way.
When talking about data product delivery, there are four foundational capabilities that you should have in place prior to the design, build and production phases:
The first step is understanding the broader business goals, the data strategy that underpins that and the needs of your business stakeholders. You ensure the product will be strategically aligned by interviewing and workshopping with business leaders and stakeholders from the outset. This doesn’t end with the discovery phase; book check-ins and updates with these stakeholders to facilitate buy-in and user acceptance.
📝 Related Reads
Issue #7 - The Business Strategy, Where The Data Journey Starts
The next step is the foundational tooling below the data product. Teams need to consider four things in sequence. First, what is the overall enterprise & technology architecture within the organisation? Hopefully, the organisation has built its technology stack strategically and has a clear data flow from source to consumption, with the right tooling to deliver against the business requirements.
Second, build some semblance of a conceptual, logical and physical data model connected to the business model or the most pertinent business processes for the identified data products…
Third, think about the solutions architecture, which translates business requirements into technical specifications and functional requirements, specifically how the data product design/ build will align with the organisation’s infrastructure. Fourth, you have the engineering. Leveraging the designs in the data modelling and solutions architecture, the engineering team should be able to design and build high-quality data assets that can scale as per data product requirements.
📝 Related Reads
Issue #19 – Developing an Overarching Data Technology Strategy
Building Data Platforms: The Mistake Organisations Make | Issue #54
The Essence of Having Your Own Data Developer Platform | Issue #9
Governance ensures that your data and underlying products are built with quality, security, scalability, and usability in mind. Frameworks should outline ownership for products, linking those to relevant data owners & stewards. Aligning this ownership with the overall data model and solutions architecture helps create transparency in the data lineage mapping and provides the basis for proper documentation.
📝 Related Reads
How to Create a Governance Strategy That Fits Decentralisation Like a Glove
How to Turn Your Data Team Into Governance Heroes🦸🏻| Tiankai Feng
With the governance established, data management is required to maintain the quality of data feeding into the product. A lot can fall into this bucket (especially because data management is such an ambiguous term).
Still, in this context, this should focus on master data management, data quality standardisation, and observability. Without this component, you will get the classic “garbage in, garbage out” result.
📝 Related Reads
Re-Engineering the Data Value Chain - Part 1 | Issue #8
With the foundations laid, it is time to build the functional and valuable data products the analytics and business teams need!
So, with a Data Product properly defined and the foundational components in place, it’s time to dive into the Data Product Operational Delivery Model.
This is a high-level view of a data product delivery (and may leave out some of the finer details), but it addresses the primary considerations within a best practice delivery approach (and trust me, I’ve overseen the delivery of quite a few products).
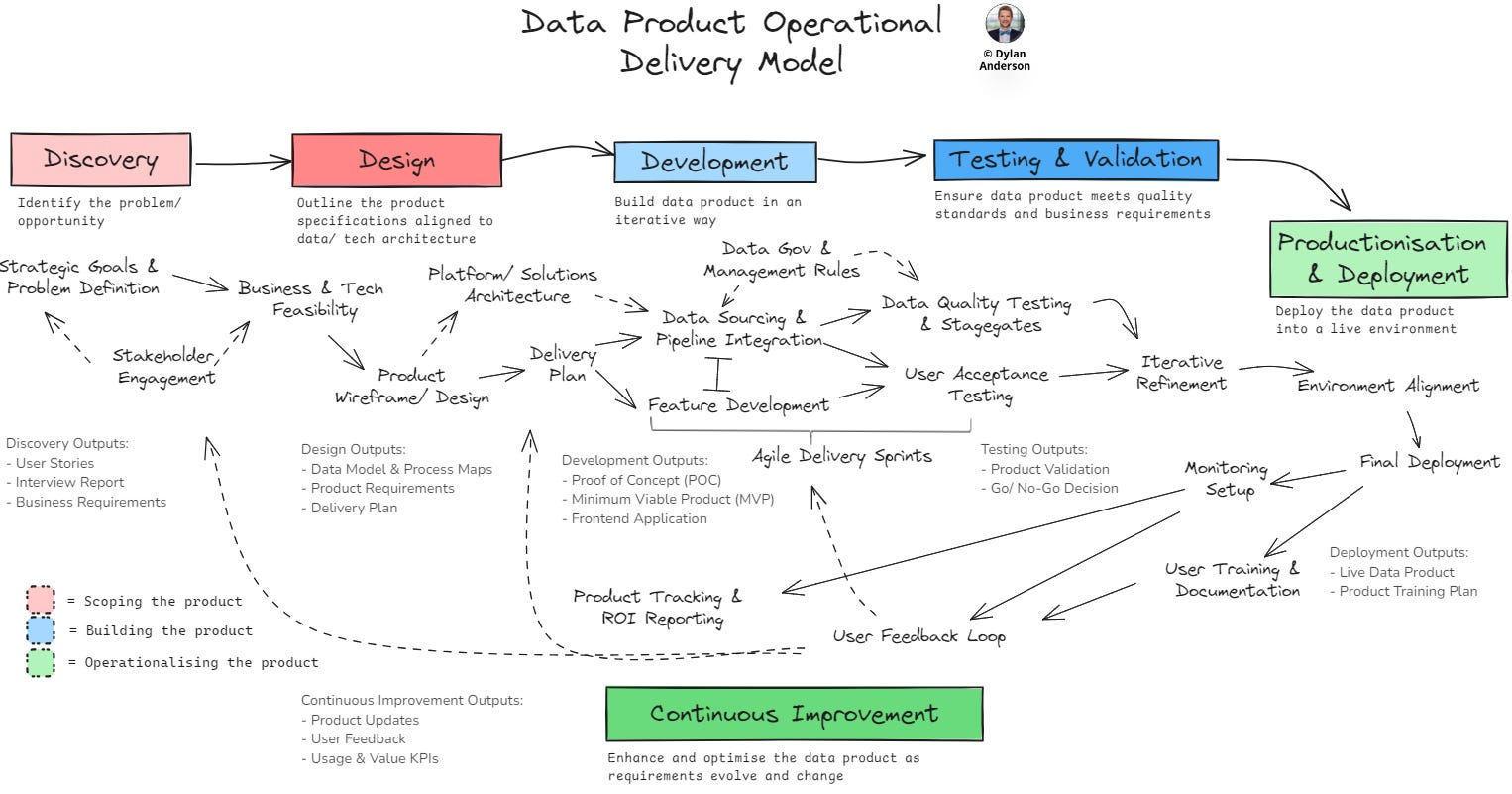
I have broken the operational model into three distinct phases with two steps each. This leaves six total steps with multiple activities and deliverables within each:
The first phase is Scoping the Data Product. This involves defining the why and how behind the data product. Before going off and building the thing, teams need to discover the problem/ opportunity and scope out the design of the data product to add value to the business.
Understand what the problem this data product is trying to solve or the opportunity it presents to the broader business.
Turn insights from the Discovery stage into requirements and design documentation to provide clear guidance for product delivery.
📝 Related Reads
Validating Data Product Prototype/DesignEnd Products of the Design StageHow to Build Data Products - Design | Part 1/4
The second phase is Building the Data Product. This should be done iteratively, allowing for business stakeholder feedback. At the same time, it needs to leverage existing foundations, with testing and validation playing a key role before rushing to production.
Use validated designs to iteratively develop the data product (both the back and front ends), building in sprints to ensure alignment with users and relevant stakeholders.
📝 Related Reads
End Products of the Develop StageHow to Build Data Products - Develop | Part 2/4
Ensuring data that feeds into the product meets quality requirements while confirming the frontend requirements for business needs.
The third phase is Operationalising & Optimising the Data Product. This entails careful monitoring of the product launch to prevent last-minute glitches or problems. Then, the team needs to understand if users understand how to use the data product and whether it is delivering against stated goals, helping inform further improvement.
Deploying the data product into a live environment ready to be used by end users
📝 Related Reads
End Products of the Deploy StageHow to Build Data Products - Deploy | Part 3/4
Seeking out feedback on the live data product and implementing updates to enhance and optimise its effectiveness.
📝 Related Reads
End Products of the Evolve StageHow to Build Data Products - Evolve | Part 4/4
📝 One from the MD101 Archives
Dylan covered several interesting nuances in the exhaustive piece. Here’s a rough overview we pulled from the archives to share a bare-bone visual summary of the end-to-end lifecycle with the outcome of each stage.
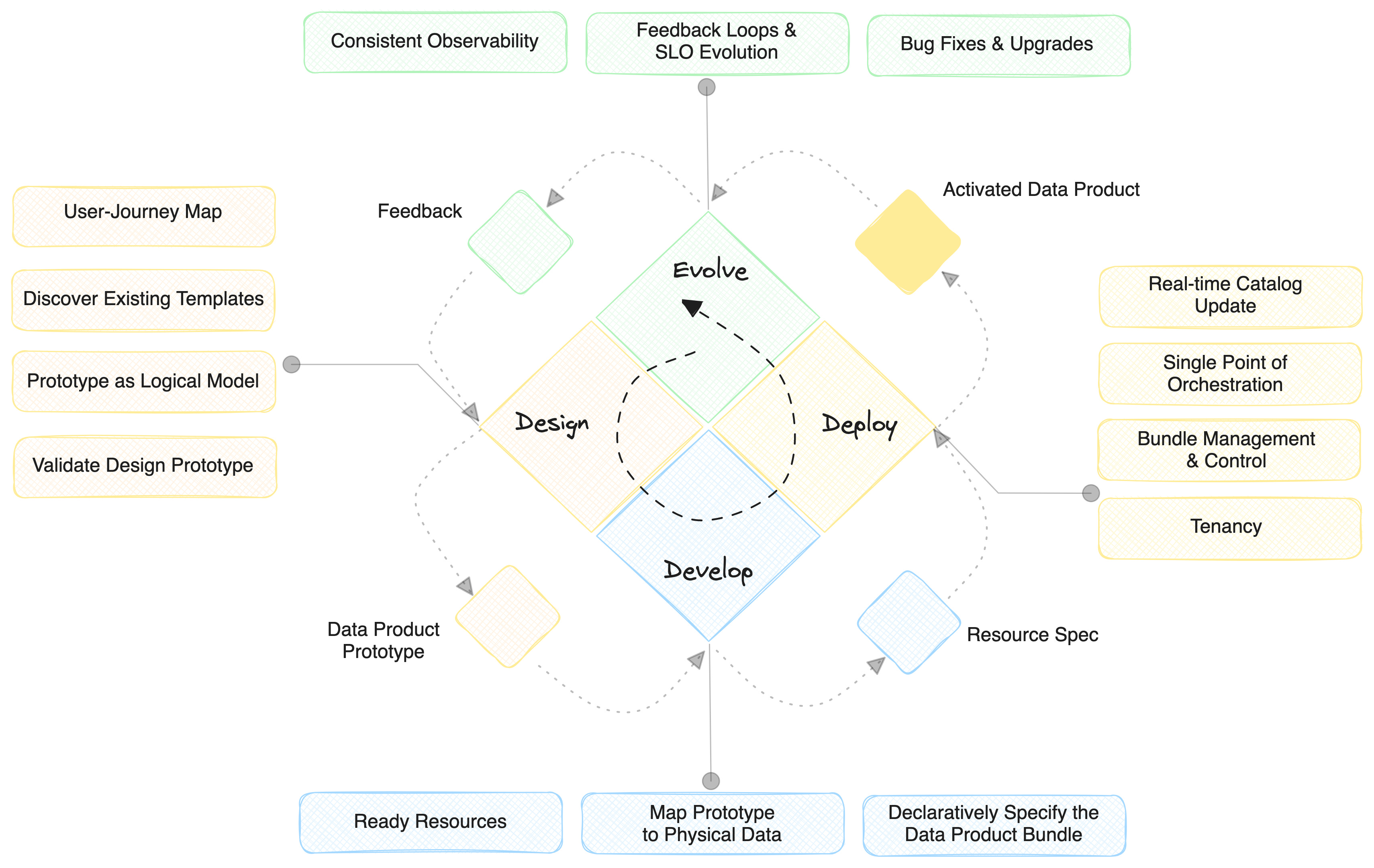
Data Products aren’t an easy subject. For many users, they are the endpoint of the data lifecycle, and everything in the Data Ecosystem leads to them.
That is why this subject of Data Products and doing it correctly is so important! When trying to prove the business value of data, the foundations and operational delivery model are essential to ensuring a data product gets used. So good luck, and I hope this article helps you put your data product development on the right track!
Thanks for reading Modern Data 101! Subscribe for free to receive new posts and support our work.
From The MD101 Team
Here’s your own copy of the Actionable Data Product Playbook. With 500+ downloads so far and quality feedback, we are thrilled with the response to this 6-week guide we’ve built with industry experts and practitioners. Stay tuned on moderndata101.com for more actionable resources from us!


Thanks for the read! Comment below and follow my newsletter for more insights! Feel free to also follow me on LinkedIn (very active) or Medium (increasingly active). See you amazing folks next week in The Data Ecosystem!

