New Release

Table of Contents
Get weekly insights on modern data delivered to your inbox, straight from our hand-picked curations!





the following is a revised edition.
Previously, we discussed how we could build great products with an emphasis on the design stage of the data product lifecycle.
Once you have completed the design stage of data products and specifically know what you're going to do, and you have clear metrics and key performance indicators in place, you can then go into the development stage and actually start building the data product.
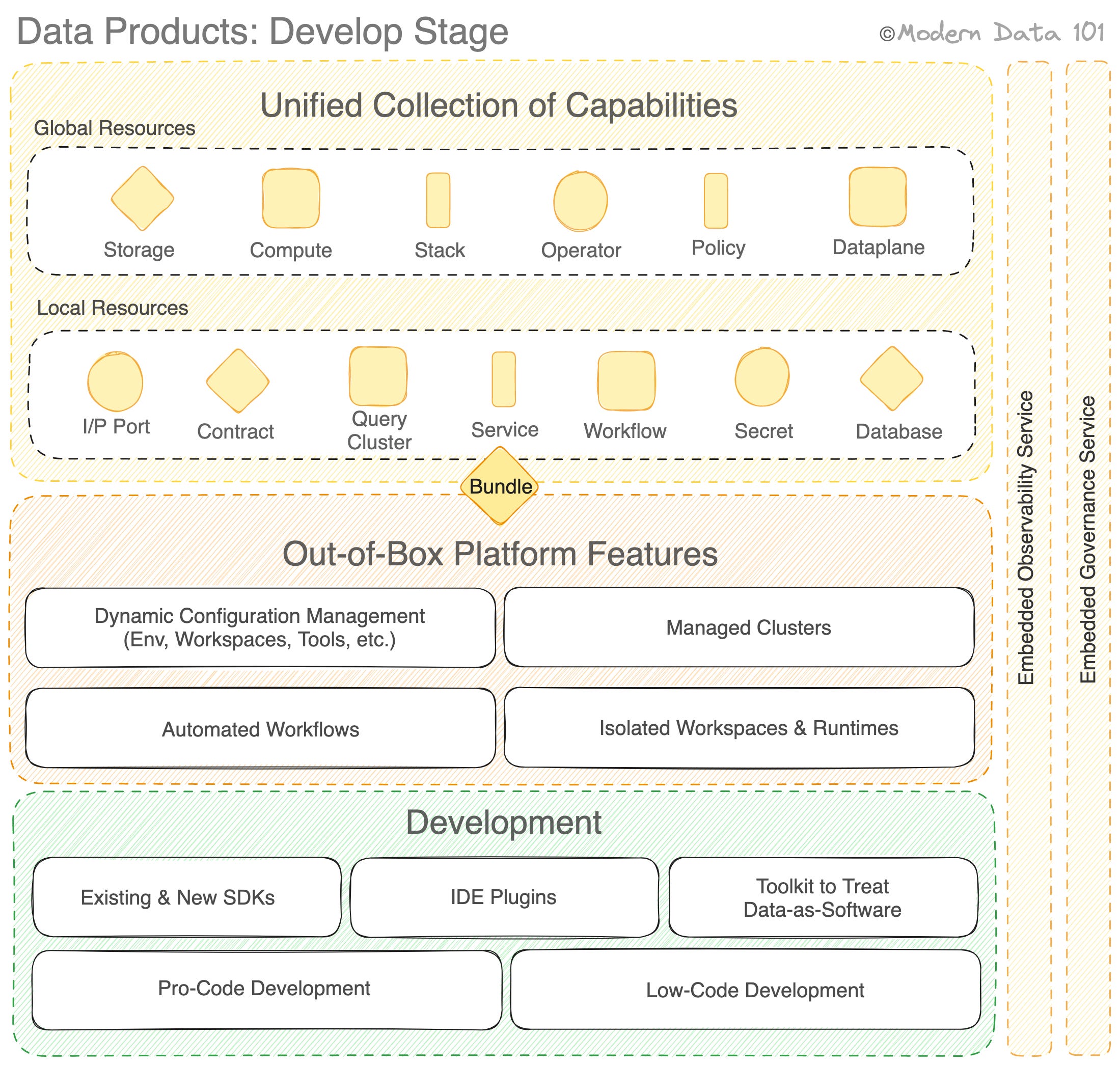
The Develop Stage is where the data product developers come into play, and business users have a minimal say and don't really participate. They are more like observers. Data developers need to know about the data pipeline and policies, quality requirements, and all other nuances of the data product.
To build a data product, first, you want all the technology stacks in place, and you want all the resources or the fundamental requirements such as depots (input ports), policies, workflows, services, compute, contract resources and more readily available to you through one common interface. The unified hood pushes up the developer experience exponentially, which is a proven precursor to the effective enablement of data-as-a-product.
Each of these fundamental resources or atomic building blocks has been defined by the Data Developer Platform Standard.
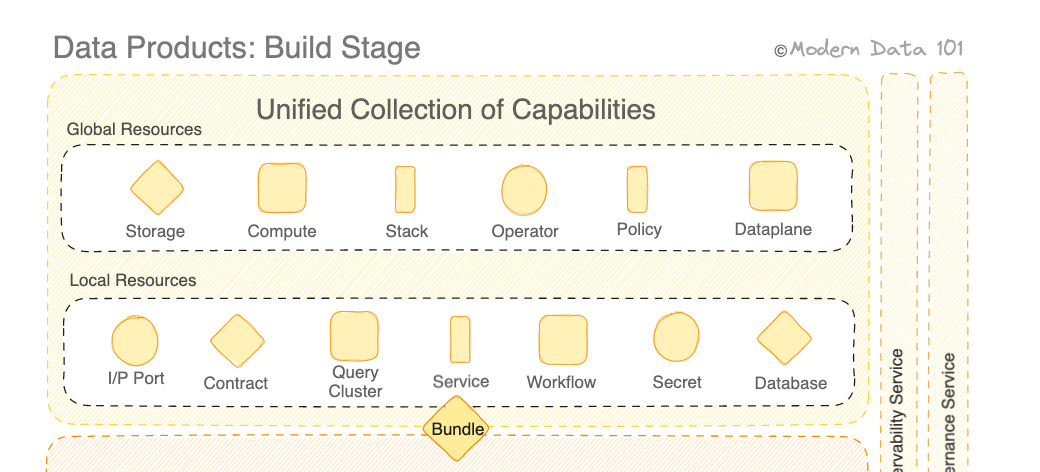
You want a way to not only write pipelines and schedule pipelines but also want a way to have long-running services where you know there is no end to the data that you're serving. You want a way to work with stream data. You want a way to work with batch data, and you want an orchestrator to orchestrate all these resources.
You want a way to deploy compute and clusters so that you know what kind of infrastructure resources are going to come into play to create that data source. And what you want, most importantly, is, across all this, a unified developer experience.
Let's say a part of your entire pipeline or a part of your entire data product is built on a tool, say, Azure Data Factory, and you're using ADF pipelines for a certain part of your data product. You want to trigger the ADF pipeline, perform CRUD operations on it, monitor it, check its status, and more from the same platform from the same interface.
You don't want your developers to use one terminal for creating workflows, another terminal for orchestrating, another interface for writing different programming paradigms, another for deploying clusters, and so on.
A data product serves a unified experience with all code in one place and the ability to interoperate across multiple limbs through one common data product DAG, or the Bundle. To enable this unified experience, interoperability is very important in the build phase.
Your data platform should be interoperable with, say, Azure Data Factory from our example, DBT, DataBricks, or any other development kit you’re using. The developers should be able to run pipelines over there from the interface that you are providing within your data developer platform.
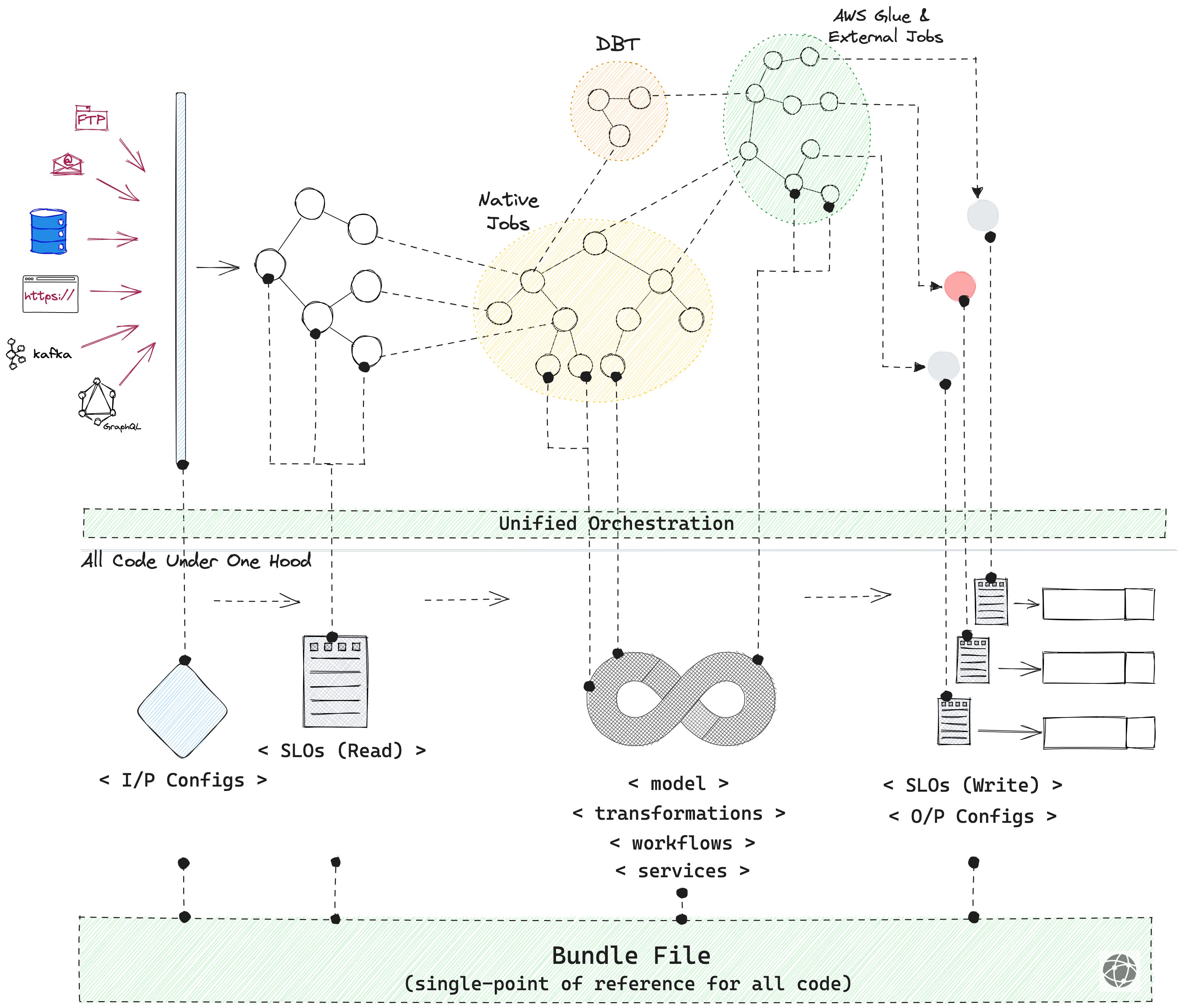
Just interoperating is easy, but interoperating from the perspective of delivering against a contract is a whole different ball game. You have to take care of how the DAGs are created, how the workflows are created, and how you monitor end-to-end consistently to maintain them at their optimum health.
Another aspect that's going to be important in the build phase is whether you are able to bring in different programming paradigms. For instance, you already have a Spark SQL in place, but now also want to use Flink. Is there an ability for the developers in the organization to start using Flink with your chosen data platform?
Or let's say the developer wants to write a Python-based program, can they do that? Does the chosen data platform have SDKs so your citizen developers don't have to just work with a terminal or CLI but can also work with APIs programmatically?
This ability to support a wide degree of flexibility is extremely important in the data product build phase and is supported by data developer platforms. Understanding to what degree you can bend the platform to match the native and familiar development environments for your developers is an important criterion during choosing a data developer platform.
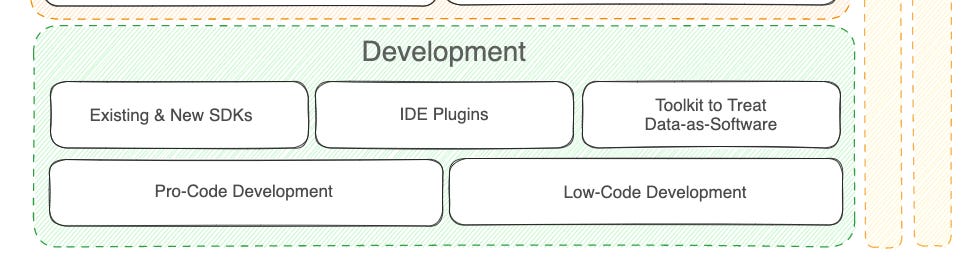
Once you’ve chosen the interfaces for development, you write code and want all of that code to be present in one place. Let’s say you have this data product called Customer which has various components.
The code for each of the above components is managed under one common repo, giving a clear perspective on the resource requirements, costs, and efforts, specifically directed to a particular business goal that the data product is empowering.
If you are a data developer and you have got the gist of what a data product is and what would be the fundamental requirements to build it, you are likely going to find all those capabilities and more within data developer platforms.
With a data product on a data developer platform, you have the ability to design, develop and truly deploy in one click when you are ready and truly have a CI/CD functionality.
Creating a data product DAG seamlessly and managing it from a single point of reference is not enough.
All the effort you’ve put into defining workflows, models, contracts, policies, and more needn’t be wasted if you’re building similar use cases or solutions for customers in the same industry or product line. You need the ability to duplicate your well-defined resources.
Due to the semantic richness of the data products and the resources within them (all first-class citizens in the catalog), they are easily discoverable based on a variety of keyword combinations. The developer teams may also choose to keep using their existing catalog by plugging in the metadata from the data developer platform’s core catalog.
So, the first thing you do is discover and go through the already existing data products and then within those data products, you can check all the workflows, policies, depots, contracts and all the other resources which have already been defined to create that particular data product.
Developers can even search by workflows and then drill down into specific jobs or resources within. You can find all the details around that workflow, its DAG, its code, compute usage, and can also check the run history and success history. The developers have all the details on how the workflow was used and the context around the feasibility of using it for a new purpose.
If all looks well, you can go ahead and use the pre-defined resource (workflow, service, contract, etc.) for any new data product development track.
In order to build pipelines, you need a workflow which is nothing but a DAG. You write jobs and have dependencies in place. You also manage pipelines both within and outside the native data developer platform, which has the ability to generate inside→out triggers and accept outside→in triggers.
This enables the data platform to orchestrate the entire Data Product DAG, even with multiple tools in the mix. You can trigger this pipeline, you can perform CRUD operations on that pipeline, monitor it, check its state, and perform many more functions.
Note: Unified orchestration is a development choice and developers can also choose to work with fragmented orchestration and yet build a continuous DAG with inside→out and outside→in triggers.
Developers can decide what resources go into the workflows of the Data Product DAG. Every dynamic variable, resource or code, is a parameter input and, therefore, a dependency. The workflows and jobs are config-based and are dynamically managed in case of upstream changes.
For example, typically, if you have to run a spark job, you will write it in Java, Go, Python, etc. You will build, you'll create an image, and then you'll deploy it. Now, say, if you have to add one more transformation step, you'll go back, you'll write it again, you'll create the build again, and wait it out.
In a dynamically configured transformation, you can just define the configuration, which comes in the format of:
That’s about it. Now every time you go and change these configurations, you need not re-deploy your image.
Interestingly, a data developer platform also allows developers to combine multiple workflows where each workflow has multiple jobs. This allows developers to build as complex a pipeline as they want, and with dynamic configuration management, isolation of workspaces and environments, and automated workflows and testing, they can keep the complexity out of managing the super-workflow.
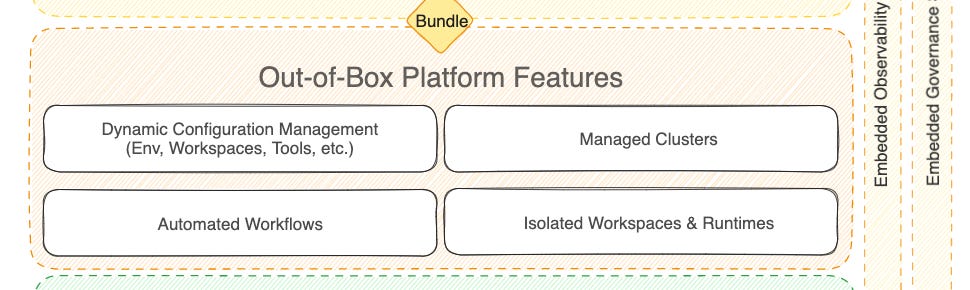
So at the end of the Develop Stage, what you want is that all these different things that went into creating the data product, the assigning of compute, assigning of creation of policies, creation of writing workflows, all these things should not be segmented, or be separately managed and triggered manually.
You want all of these elements to come together as a DAG where you can exactly define steps like connecting to source systems, writing input policies and quality scans, as many transformations as needed, and, again, policies and quality checks for every output port.
In a condensed form, these are the essential capabilities necessary to enable the data product develop stage:
All these interfaces and capabilities necessary for the Data Product Develop Stage are furnished by data platforms modeled after the Data Developer Platform Standard, alongside other interfaces for the other stages of Design, Deploy, and Iterate - all under one unified hood instead of a fragmented tooling experience.
While we continue navigating the data space and curate effective data as a product strategies, it becomes essential to focus on the discreet phases of the data lifecyle management to be able to derive the optimum outcome from your processes and the data itself.

