New Release

Table of Contents
Get weekly insights on modern data delivered to your inbox, straight from our hand-picked curations!




the following is a revised edition.
Let’s know what is a data pipeline?
Generally defining it, a data pipeline is a combination of technologies and processes for moving data from a source to the destination like a data lake, while optimizing it into a state where it can be analyzed and leveraged for business insights. (Source: https://www.snowflake.com/guides/data-pipeline/)
Read more about a data pipeline example and data pipeline architectures in this section of the article: How to Build Data Products - Deploy: Part 3/4
Data pipelines are one of the key components of the data economy. Creating value from different resources only makes sense when it is available to the consumers. We are used to turning on the lights, opening the tap to drink water, and putting gas in the car without thinking about the underlying transport of those goods.
In the data product context, we rely on data pipelines to transport the value generated to the consumers. They are not the “end product”, but they serve the bigger purpose of delivering that value to be used by different consumers.
In many cases, data pipelines are the bigger source of headaches for data teams. Ad-hoc development, lack of standards and visibility, and spaghetti lineage are the day-to-day issues that derail the attention to fixing specific issues rather than extracting the full value from the data products.
The reality must be different. We need to shift our mindset from a support standpoint to the core role data pipelines have in the value chain of data products. In the article, we will explore the most important elements of a data pipeline that fulfills the data product needs, and you will get practical guidelines to incorporate in your use cases.
Before getting started, we need to align on the definition of a data product to set the proper context. The concept of data product comes from the data mesh architecture, and according to J. Majchrzak et al.:
Data product is an autonomous, read-optimized, standardized data unit containing at least one dataset (Domain Dataset), created for satisfying user needs
I like timo dechau 🕹🛠 ’s perspective from the product management standpoint that think of it as:
An internal data product is an application that uses data to make the next action immediate
I highly recommend his article to dive deep into that perspective: The Go-To Metrics for Data Products: Start with these Few
I see data products as something between those definitions. It is a data asset that can be used to produce value. I like the “make the next action immediate”, but sometimes a valuable data product could be a building block to something bigger.
Related Read: The Data Product Strategy | Becoming Metrics-First
Benefits of data pipelines can be guaged across differetn aspects. Data pipelines generate and transport value. The simplest example is water pipelines. They are used to transport water from a river, it goes through some treatment to become drinkable, and other pipelines move it again to our houses. In the data context, they are the primary driver of data products, transporting other assets (ingestion), combining and improving them (transformation), and making the final product available for consumers (service).

The Data Product Canvas is an excellent asset for data product definition. In the design phase, it recommends we define the ingestion, storage, transport, wrangling, cleaning, transformation, enrichment, and so on. Sounds familiar? That is what data pipelines do. In fact, the data pipeline will be in charge of generating not only the output but metadata and metrics that will enable different features of the data product.
Things like schema, security, quality, and operational metrics, could and should be generated within the data pipeline and propagated to the corresponding systems.
How is that related to the “data as a product” concept? Data as a product is the second principle of the data mesh, and Zhamak Dehghani defined it in How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh.
For a distributed data platform to be successful, domain data teams must apply product thinking with similar rigor to the datasets that they provide; considering their data assets as their products and the rest of the organization's data scientists, ML and data engineers as their customers.
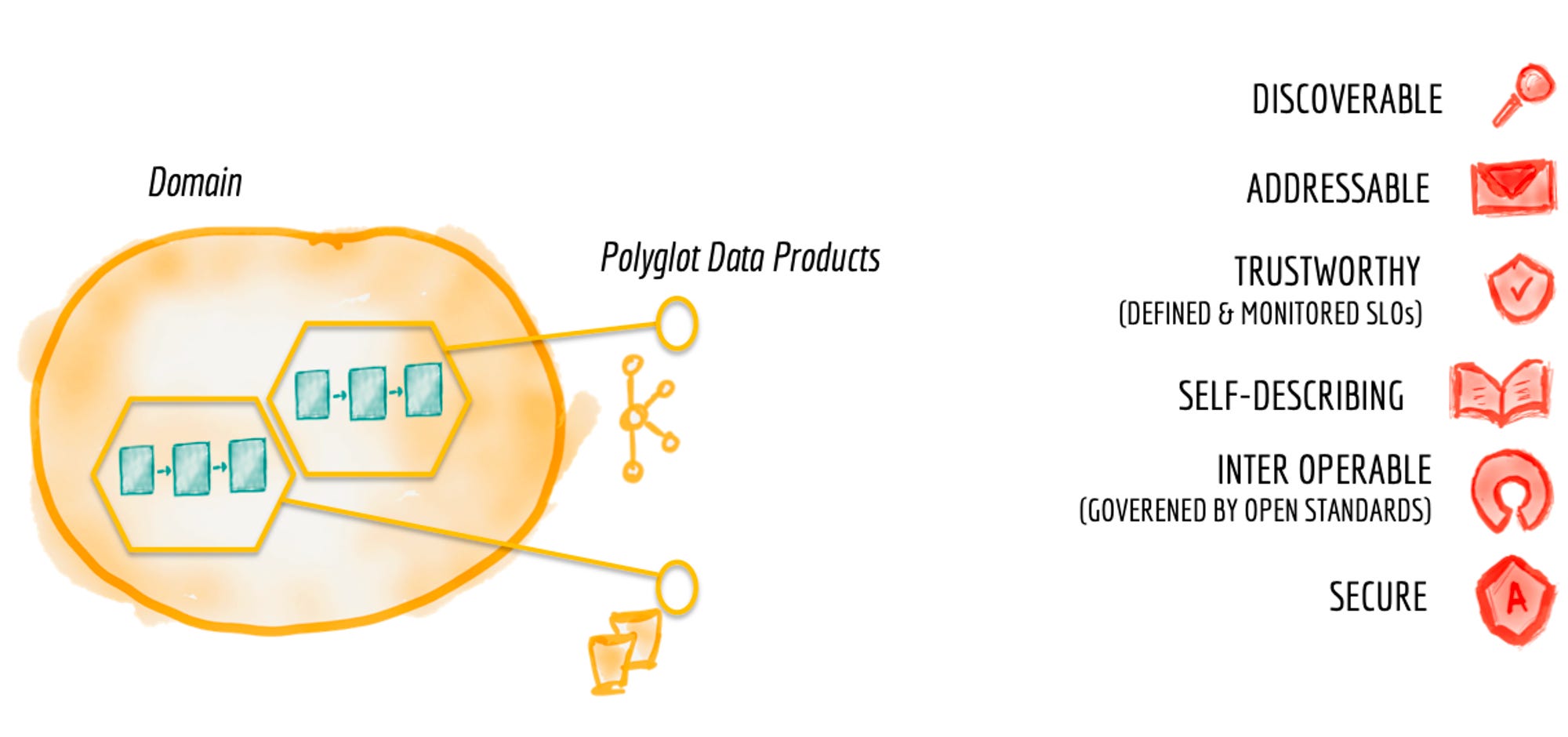
Data products must have those qualities in mind: discoverable, addressable, trustworthy, self-describing, interoperable, and secure. The data pipeline will enable those features by abstracting the complexities and providing high-level components that serve multiple domains. If this sounds interesting, Zhamak describes the capabilities of a self-serve data infrastructure in this section of the article mentioned above.
How to Build Data Products? | Design: Part 1/4
Also, one on Fitness Tests: www.datamesh-architecture.com/fitness-test
Before getting into the key components of the data pipelines, it is worth considering Zhamak’s perspective, where she describes some architectural failure modes, and one of them is the coupled pipeline decomposition.
Given the influence of previous generations of data platforms' architecture, architects decompose the data platform to a pipeline of data processing stages. A pipeline that at a very high level implements a functional cohesion around the technical implementation of processing data; i.e. capabilities of ingestion, preparation, aggregation, serving, etc.
In that section, she emphasizes that the problem comes from the components (ingestion, processing, serving) we generate that slow the delivery of new features. Why? Because enabling a single new feature requires a change in all components of the pipeline.
I understand her point but disagree with how she generalizes that coupling. First thing, not all ETL processes are running in a single pipeline. Nowadays, it is expected to have an orchestration tool (Airflow, Dagster, Prefect, Mage) with multiple pipelines that allow the reuse of different components and use configuration to easily set up new pipelines without changing all components, as Zhamak pointed out.
The key components of data pipelines will be aligned with the data product qualities mentioned before and the self-serve data platform principle.
Related Read on key components of a Data Product DAG
How to Build Data Products? | Build: Part 2/4
If we want to iterate fast and add value with data products, we need to automate the orchestration of the pipelines. Two main types of models could define the type of orchestration to use: push and ingest, and serving and pull. We can think about them as traditional batch processing and data streaming, respectively.
In data mesh, there is a preference for the serving and pull model, but it is not suitable for all use cases, and even if it is applicable, we would need some kind of orchestration.
Many commercial and open-source tools allow us to orchestrate pipelines in the form of direct acyclic graphs (DAG), and I would add that we should add automation on top of them. It could be a CI/CD tool or trigger actions when the pipeline code is pushed to the central repository. By having automated orchestration, we can focus on adding value to the data product and forget the nuances of deploying and running the pipeline code.
Recommended tools: Airflow, Dagster, Prefect, Mage.
1. Jump to section on unified orchestration models for Data Product DAGs
2. How to Build Data Products? Deploy: Part 3/4
One of the pain points Zhamak described about pipelines was the delivery speed because we might need to change many pipeline components to add new sources. Data ingestion is now a commodity with tools like Airbyte or Fivetran, where we have hundreds of connectors from any source in minutes.
The recommendation is to use those tools that are maintained and improved by other teams, giving us the flexibility and speed to deliver value faster. If you are developing or maintaining data ingestion operators, consider using one of those tools to standardize it.
Recommended tools: Airbyte, Meltano, Fivetran.
Jump to implementation of Standardised Ingestion points or Depots as Input Ports.
Data quality is a fundamental pillar of data products. One of the qualities we look for data products is trustworthiness, and to achieve that we need to focus on data quality.
Shift-left data quality means incorporating data quality checks as early as possible in our data pipelines. The first thing we can do is validate data contracts from input data assets, like the schema or important attributes we use in our processing and enhancement.
You would argue that if everyone follows the same rules, publishing their data products with the expected quality and SLOs, that shouldn’t be necessary, but let’s face the reality that perfection doesn’t exist, and sometimes the input data comes from a third-party tool or source that doesn’t follow the same guidelines as we have.
If the source doesn’t provide a data contract, we can still incorporate data quality checks that will ensure the validity of the input data. That will prevent downstream failures in the processing and data contract violation of the data product we are generating.
Apart from schema and contract validation, data quality checks can be implemented in multiple steps along the pipeline, and we can use data catalog tools to publish metrics about the data products we are creating.
One of the common traps we can fall into is fixing data quality issues as part of our transformations or adding a cleaning step for problems on input data. That is a good practice in some cases, but we shouldn’t normalize fixing upstream data quality issues as part of the pipeline duties. If the data sources are violating the contract or something is not specified in the contract and causing issues, we must raise the problem with the corresponding owner to fix the source and, if necessary, make changes in the data contract to add that information.
Recommended tools: Great Expectations, Soda, Monte Carlo.
1. Jump to Right-to-Left Engineering and Shifting Data Ownership
2. Data-First Stack as an enabler for Data Products
If we want our data products to be discoverable, we need to provide information about which sources we are using, what we are doing with them, and where we are serving the data product. That can be accomplished by using a data catalog and providing data lineage information about our data product.
The data catalog is a centralized repository of information, and it is a fundamental component to enable data product discovery and usage. This centralized repository allows data consumers to find the dataset of their interest easily.
As part of our pipeline development, we need to publish the information about our data product in a data catalog, specifically lineage data, to allow consumers to find connections between data products and simplify root cause analysis when something fails.
Most data catalog tools have data lineage capabilities to incorporate and visualize that information alongside other data product metadata. Other tools like dbt automatically generate lineage metadata, and in the cloud version, we can also visualize it in the lineage graph.
Data lineage is still a green field, and as data pipeline developers, we will need to integrate different solutions to generate and store lineage data. A group of developers is working on an open standard named OpenLineage with great specification and integration with broadly used tools like Airflow, Spark, and dbt.
Recommended tools for data catalog: DataOS, DataHub, Amundsen, Atlan.
Recommended tools for data lineage: OpenLineage, Marquez, Alvin, dlt.
Recommendation from Editors: DataOS Metis Catalog Purpose-Built for Data Product Resources and DAG
1. Jump to section on populating the data catalog with Data Product as first-class entity
2. How to Build Data Products? Deploy: Part 3/4
As mentioned in the ingestion section, many tools and services allow you to move data to different destinations, so there is no need to build custom operators for that.
Part of serving data as a product is related to publishing data quality metrics, metadata about schema and semantics in the form of a data contract, and respect SLOs defined with consumers. This must be another set of components that validate its own data contract and move the data to the destination (or make it available).
If the data product we generated doesn’t fulfill the constraints, we must notify consumers and even prevent new data from reaching the destination. You can use the write-audit-publish pattern in conjunction with data quality tools.
Recommended tools: Data Contract Specification.
The Data Contract Pivot in Data Engineering
As data practitioners, we need to understand the importance of data pipelines in the context of data products. They ensure that value is not just generated but is also made accessible. They are often a source of challenges, needing a pivotal shift from a support role to a core component in the data value chain.
If you want to apply the concept of data as a product, you must incorporate these key components in your data pipelines:


